Thinking Process for Solving Complex Problems


Introduction
In the world of software integration, complex problems can often emerge unexpectedly, and tackling them effectively requires a systematic approach. In this article, we’ll share our journey of addressing a persistent issue within our company — duplicate records — which arose during the integration of a Point of Sale (POS) system with our system. Rather than focusing solely on the technical details of the problem, we’ll delve into the thinking process and strategies that guided us through the resolution. This thinking process can be applied to various technical challenges you might encounter.
Steps to Find the Solutions
1. Drawing an Overview of the Pipeline
Our problem-solving journey began with a critical first step: drawing a comprehensive overview of the integration pipeline. This involved mapping out the systems involved and detailing the events that occur within this pipeline. Understanding the big picture was crucial to identifying where the issue might be originating.
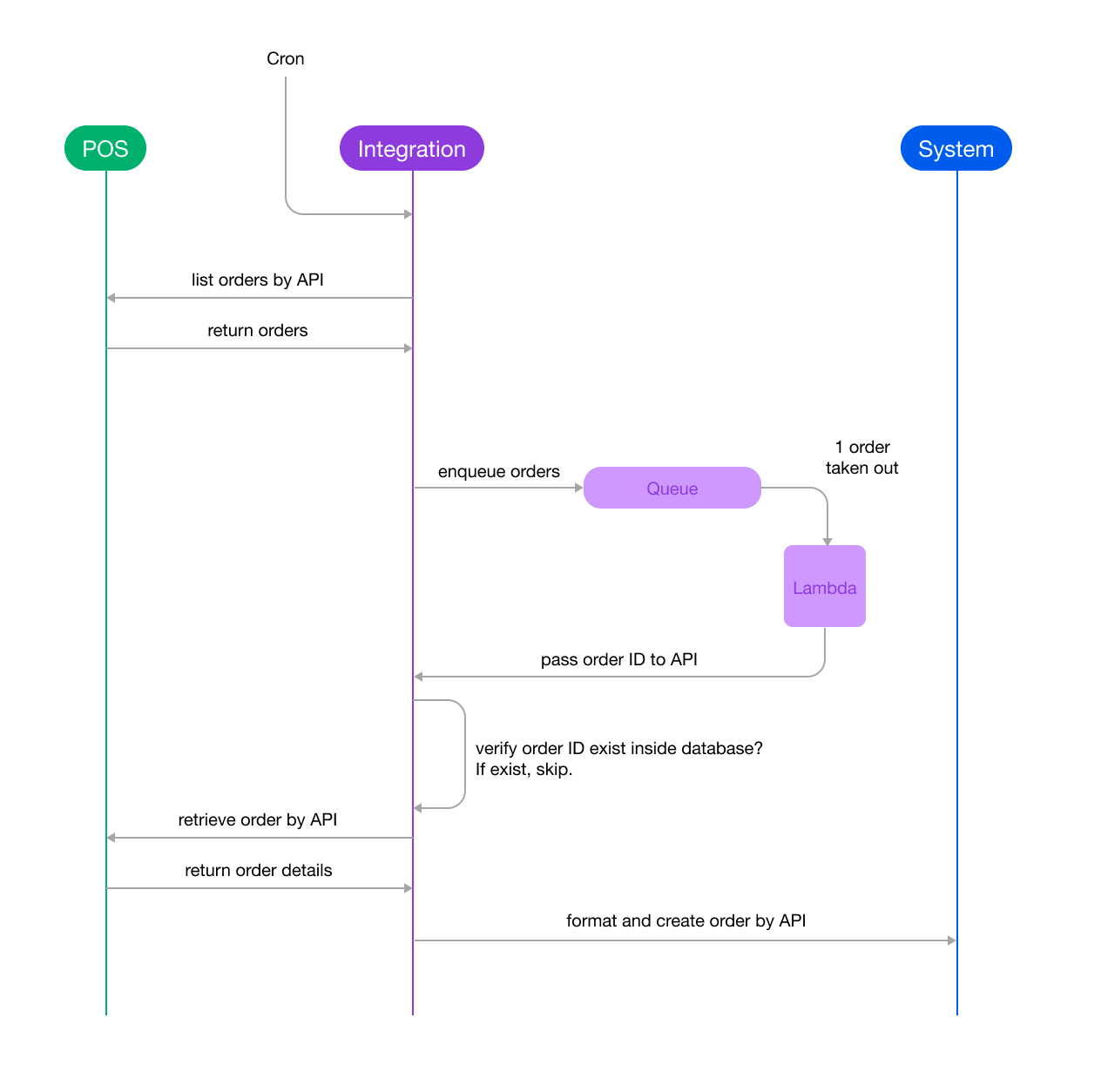
2. Identifying Potential Causes
With a clear understanding of the integration pipeline, we embarked on a brainstorming session to identify potential causes of the duplicate order issue. We recognized three key areas to investigate:
- Lambda Concurrency: Could the concurrent execution of Lambda functions be contributing to the problem?
- Lambda Retry: Is the Lambda retry mechanism responsible for duplicate orders?
- Duplicate Orders in POS System: Are there duplicates being generated in the POS system itself?
3. Analyzing Potential Causes
We then delved into each potential cause, seeking to eliminate uncertainty by ruling out any excluded reasons. During this investigation, we were able to determine that duplicate orders in the POS system were not the root cause of the issue.
4. Brainstorming Solutions Based on Causes
With our list of potential causes narrowed down, we engaged in brainstorming sessions to propose solutions that could address the remaining issues. Our proposed solutions included:
- Idempotency on API Requests: Making API requests idempotent to ensure that resending the same request doesn’t create duplicates.
- Implementing a Global Lock by Cache for Same Requests: Preventing concurrent requests from creating duplicates.
- Unique Keys Implementation on Database: Ensuring uniqueness at the database level to prevent duplicate entries.
5. Evaluating Solutions’ Effectiveness
Following the brainstorming sessions, we carefully evaluated the proposed solutions to determine their effectiveness in resolving the issue. Our assessment led us to the conclusion that implementing unique keys in the database was the most effective way to control the uniqueness of orders.
6. Performing Quick Experiments on Chosen Solutions
To put our selected solution into action, we added a new table with a composite primary key to enforce uniqueness in the database. During this process, we noticed a scenario: Lambda requests were timing out after 30 seconds.
Root Cause
Further investigation revealed the root cause contributing to the issue.
When a Lambda request times out after 30 seconds while waiting for a database result, it triggers retries and sends additional requests to our app endpoint, potentially causing multiple requests to stack up. Even if the initial Lambda request had already timed out, all stacked requests receive the same cached result from the database simultaneously, leading to the simultaneous creation of orders.
This issue can be illustrated as follows:
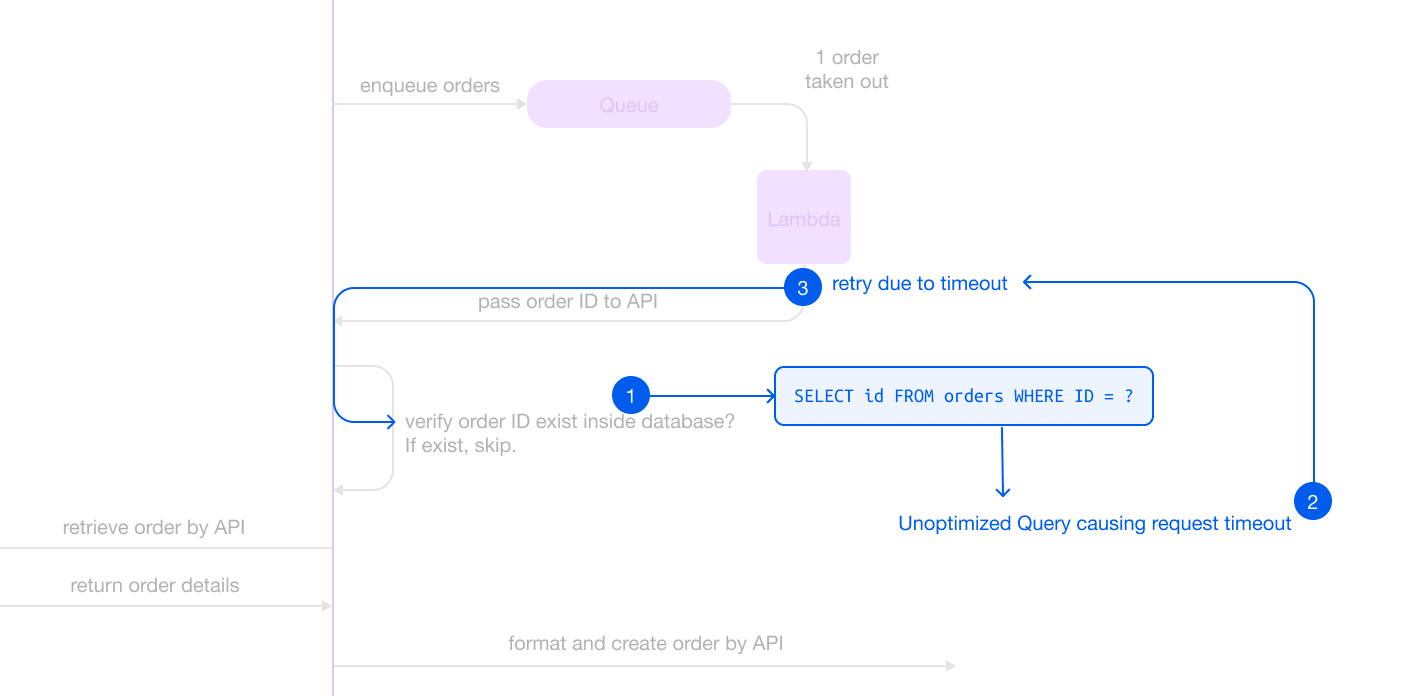
- In the request, a query executed to verify the specific order ID’s existence in the database to prevent duplication.
- However, the query took too long to get a result, causing the Lambda invocation to timeout and initiate a retry.
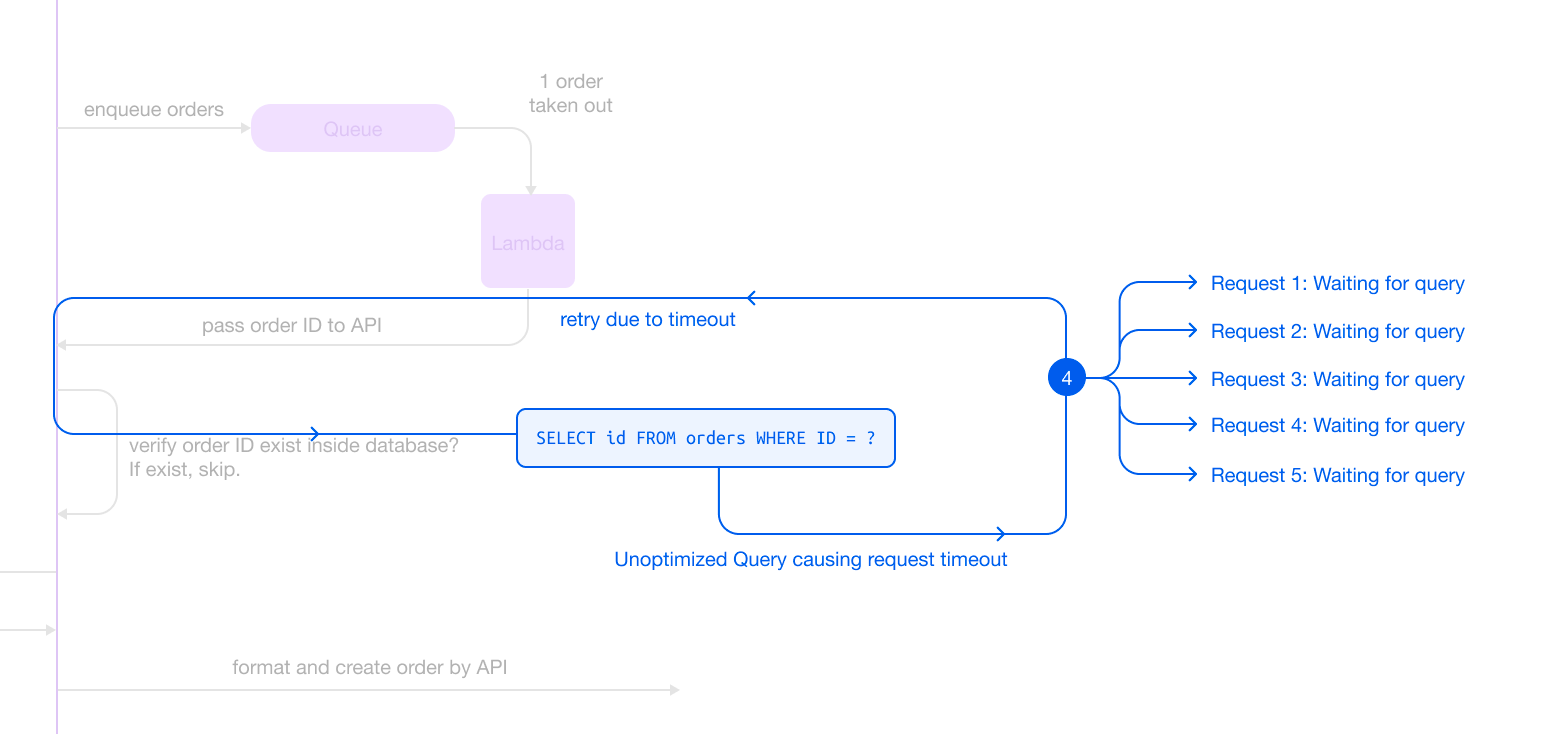
- Another request was called and got stuck at the same query, just like the first request, within the application process.
- Multiple requests then stacked up and waited for the query result.
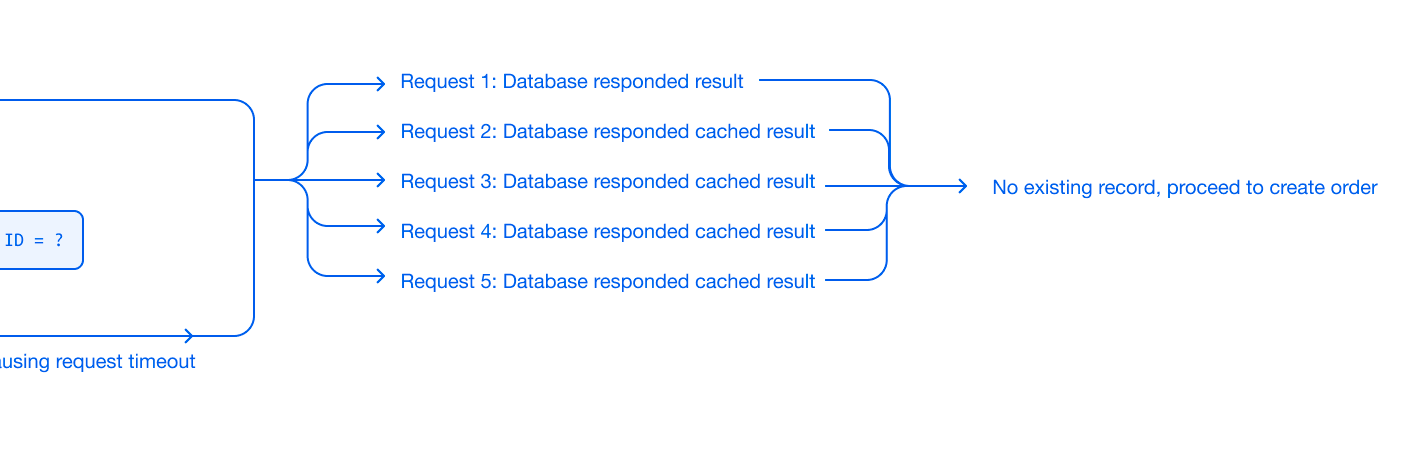
When the first request received its query result, it was cached by the database. All other requests received the same cached result simultaneously, resulting in multiple orders being created.
With the root cause identified, let’s explore how we addressed the issue.
Solution
To address the timeout issue and subsequent retries, we implemented two key solutions:
- Optimizing the Query: We optimized the database query by adding an index, which reduced the query execution time and prevented timeouts.
- Implementing Unique Keys in the Database: As initially planned, we implemented unique keys in the database to prevent duplication at the database level.
Conclusion
In resolving the duplicate order issue in the integration between the POS system and our system, several key takeaways emerge:
- Drawing an overview of the pipeline is crucial for understanding and devising solutions.
- Breaking down complex problems into smaller, manageable components is an effective problem-solving strategy.
- Increasing transparency by addressing uncertainties, adding monitoring, and logging can lead to faster issue resolution.
- A systematic approach to problem-solving, consisting of the seven steps outlined in this article, can be applied to various technical challenges.
1. Drawing an Overview of the Pipeline
2. Brainstorming Potential Causes
3. Discussing Potential Causes
4. Brainstorming Solutions Based on Causes
5. Evaluating Solutions’ Effectiveness
6. Performing Quick Experiments on Decided Solutions
7. The process can be repeated between steps 2 and 6
By following these steps and continuously iterating through the problem-solving process, you can tackle complex integration issues effectively and maintain the integrity of your data.