Elevating Web Experience: A Refined Approach to HTTP Caching


Introduction
At our company, we’re always striving to deliver the best web experience to our users. Part of this mission involves optimizing our HTTP caching strategy. Recently, we discovered a common practice in our codebase — using no-cache, no-store, and private directives to ensure data accuracy at the expense of potentially slower load times. While this approach was aimed at preventing user confusion when content changes occur, we’ve decided to rethink our strategy. Today, we’re sharing our journey to find a better caching solution that provides both data freshness and optimal performance.
Reevaluating Cache Directives
The use of no-cache, no-store, and private directives can be quite effective in guaranteeing users always see the most up-to-date content. However, it often results in retrieving data from the origin server every time, which can lead to slower page load times. To address this, we’re focusing on two primary challenges:
1. Dynamic Script Content
A significant challenge arose with dynamic script content, which evolves based on user actions. To harmonize caching with these updates, we’re shifting our approach. Instead of entirely bypassing caching, we’re now appending a timestamp as a query parameter to the script’s URL. Here’s the transformation:
Before: `example.com/scripts.js` (fetching the latest content)
After: `example.com/scripts.js?t=1232345` (ensuring fresh content after every update)
By introducing this timestamp parameter, we’ve ensured that whenever a user modifies their settings, the script URL changes, prompting the browser to fetch the most recent version. This way, we maintain data accuracy without compromising on performance.
Cache Control for Dynamic Script Content
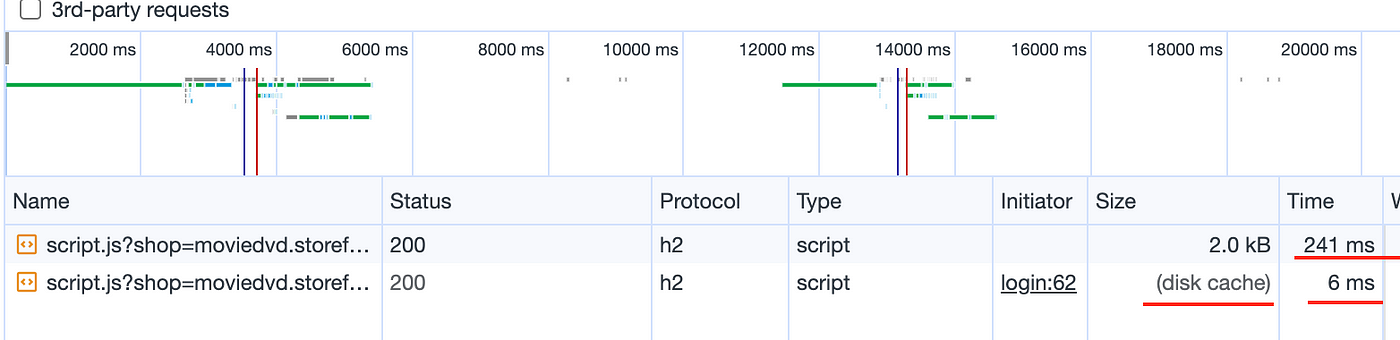
After implementing the timestamp parameter solution for dynamic script content, we set the cache control to `public, max-age=3600`. This allows the browser to cache the script content for up to an hour, providing a balance between data freshness and optimal performance.
Result:
Leveraging ETag and Must-Revalidate Strategy
In cases where script content is updated by us, rather than by the user, we sought a solution to prompt the browser to fetch the latest content without entirely bypassing caching. We’ve decided to implement an ETag and must-revalidate strategy. While this approach still involves a call to the origin server, it significantly reduces data transfer, optimizing both performance and data accuracy.
The Process in Action
To clarify the process:
1. When a request is sent to the server without an If-None-Match request header, the server responds with a 200 HTTP code and includes an ETag in the response header.
2. The browser caches the script content and retains the ETag value.
3. In subsequent requests, the browser appends the If-None-Match request header with the ETag value from the previous response.
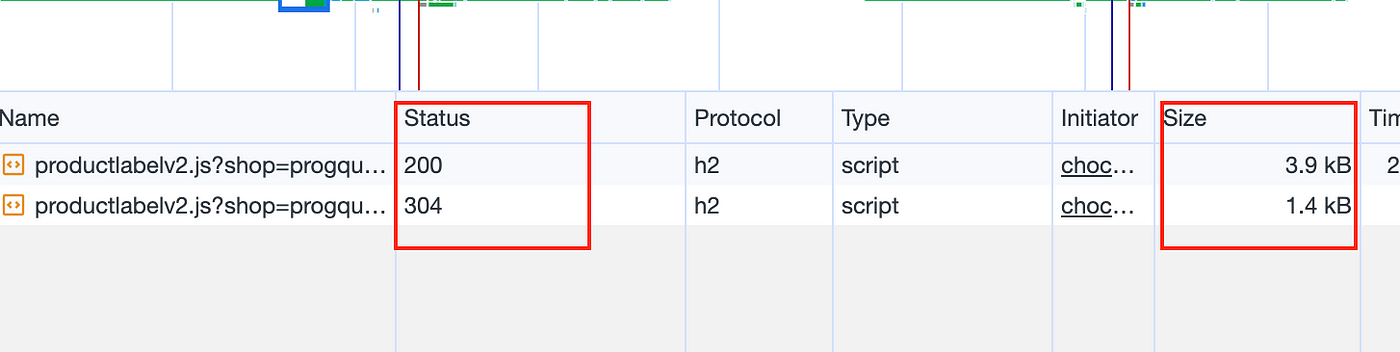
4. The server validates the If-None-Match header. If the content is unchanged, it returns a 304 HTTP code with an empty body. The browser serves the content from its cache. Otherwise, it reverts to step 1.
Result:
Conclusion
Our journey to enhance HTTP caching reflects our commitment to providing the best possible web experience. By reevaluating and fine-tuning our approach, we’re confident that we can deliver faster load times and reduced server load without sacrificing data freshness.
With these improvements, we’re poised to elevate the user experience to new heights. We look forward to seeing the positive impact this will have on our website’s performance and our users’ satisfaction. Stay tuned for more updates on our ongoing efforts to enhance HTTP caching!